Memory trong AI Agent
Agent Memory là gì?
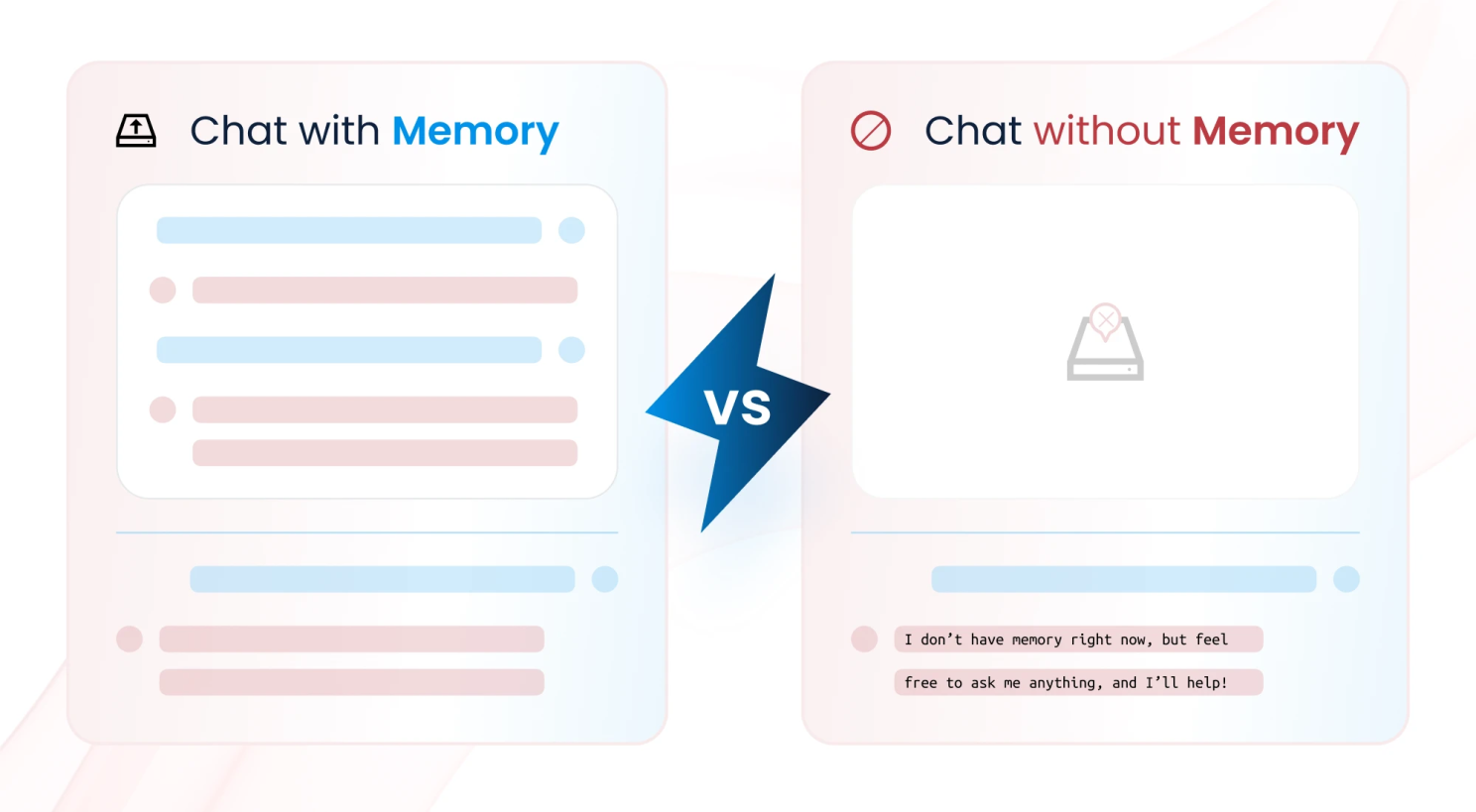
Bộ nhớ của Agent (Agent memory) đề cập đến khả năng của hệ thống AI trong việc lưu trữ, ghi nhớ và sử dụng lại thông tin từ các tương tác trước đó để ảnh hưởng đến cách phản hồi trong tương lai.
Khác với các chatbot cơ bản, vốn xử lý từng câu hỏi một cách độc lập thì chatbot có bộ nhớ có thể:
- Duy trì ngữ cảnh hội thoại.
- Cá nhân hoá trải nghiệm tương tác.
- Hỗ trợ các cuộc trò chuyện nhiều lượt (multi-turn conversations).
Ví dụ, trong môi trường chăm sóc khách hàng, chatbot có bộ nhớ có thể ghi nhớ tên người dùng, các yêu cầu trước đó, hoặc vấn đề chưa được giải quyết, từ đó mang đến trải nghiệm cá nhân hóa và hiệu quả hơn.
Tại sao Memory lại quan trọng và Khi nào cần sử dụng
“Memory is application-specific” - Langchain
→ Bộ nhớ của chatbot được thiết kế và sử dụng tùy theo mục đích và ngữ cảnh của ứng dụng. (Nói cách khác, mỗi loại chatbot hay hệ thống AI sẽ có cách triển khai bộ nhớ khác nhau, tùy vào việc nó được dùng để làm gì)
- Chatbot hỗ trợ khách hàng → chỉ cần nhớ tên, vấn đề và lịch sử yêu cầu gần nhất.
- Trợ lý cá nhân (AI assistant) → cần nhớ sở thích, thói quen, và lịch sử tương tác lâu dài.
- E-commerce → cần nhớ sản phẩm đã xem, giỏ hàng, hoặc các giao dịch trước đó.
1. Duy trì ngữ cảnh trong các cuộc hội thoại nhiều lượt (Multi-turn conversations) Bộ nhớ giúp chatbot theo dõi mạch hội thoại một cách tự nhiên và liền mạch. Ví dụ: Người dùng: “Giờ mở cửa của cửa hàng là khi nào?” Chatbot: “Chúng tôi mở cửa từ 9h sáng đến 9h tối. Bạn có muốn biết giờ mở cửa của từng chi nhánh không?” Người dùng: “Có, chi nhánh trung tâm thì sao?” Nếu không có bộ nhớ, chatbot sẽ không hiểu rằng câu hỏi tiếp theo đang nhắc đến “giờ mở cửa” , và có thể phản hồi sai ngữ cảnh.
2. Cá nhân hóa trải nghiệm (Personalization) Bộ nhớ cho phép chatbot ghi nhớ sở thích và thông tin cá nhân của người dùng — như chế độ ăn kiêng, thể loại phim yêu thích hoặc lịch sử tương tác. Điều này giúp tạo cảm giác gần gũi, thân thiện và gắn kết hơn giữa người dùng và chatbot.
3. Duy trì liên tục trong nhiệm vụ (Task continuity) Nhờ bộ nhớ, người dùng có thể tiếp tục thực hiện các tác vụ dang dở mà không cần bắt đầu lại từ đầu. Ví dụ: chatbot thương mại điện tử có thể nhớ những sản phẩm người dùng đã thêm vào giỏ hàng trong phiên làm việc trước đó.
4. Nâng cao hiệu quả (Improved efficiency) Bằng cách lưu trữ và truy xuất dữ liệu liên quan, chatbot có thể giảm các thao tác lặp lại và tiết kiệm thời gian cho cả người dùng lẫn doanh nghiệp.
Phân loại Memory
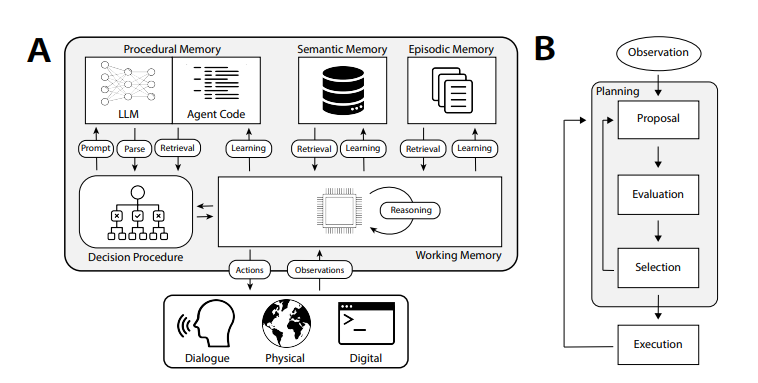
Mặc dù cách triển khai bộ nhớ của từng hệ thống AI hay agent có thể khác nhau tùy theo ứng dụng, nhưng nhìn ở mức độ khái quát, có thể phân loại ra một số dạng bộ nhớ chính. Những loại bộ nhớ này không mới — chúng mô phỏng lại cách hoạt động của trí nhớ con người.
Đã có nhiều nghiên cứu thú vị nhằm liên hệ giữa các loại trí nhớ của con người và bộ nhớ của agent (tác tử AI) . Một ví dụ tiêu biểu là bài nghiên cứu CoALA.
Các loại trí nhớ ở người
- Episodic Memory (Bộ nhớ sự kiện (hoặc bộ nhớ theo trải nghiệm)
- Semantic Memory (Ngữ nghĩa)
- Procedural Memory (Quy trình / Kỹ năng / Thao tác )
- Short-Term Memory and Working Memory ( Ngắn hạn / làm việc )
- Sensory Memory (Cảm giác )
-
Prospective Memory ( Định hướng tương lai / Ý định trong tương lai )
Loại bộ nhớ Thuộc nhóm Ghi nhớ điều gì Ví dụ Episodic Memory Long-term (Explicit) Sự kiện, trải nghiệm cá nhân “Tôi đã nói chuyện với chatbot hôm qua.” Semantic Memory Long-term (Explicit) Kiến thức, khái niệm “Chatbot là một phần mềm AI.” Procedural Memory Long-term (Implicit) Kỹ năng, thao tác “Cách viết prompt hiệu quả.” .jpg)
Loại bộ nhớ Trong con người Trong agent/AI Sensory Memory Ghi nhận thông tin cảm giác trong vài giây Vùng đệm dữ liệu đầu vào (input buffer, sensor cache) Prospective Memory Ghi nhớ để làm việc trong tương lai Cơ chế lập kế hoạch, nhắc việc, trigger-based tasks
1. Short-term Memory
Human: Là dạng trí nhớ cho phép lưu lại thông tin trong thời gian ngắn — vài giây đến vài phút. Ví dụ, khi bạn:
- Nhớ gương mặt của người vừa gặp.
- Ghi nhớ nhiệt độ hiện tại sau khi vừa tra xong.
- Nhớ điều vừa xảy ra trong một bộ phim vài giây trước.
Thông tin này có thể được chuyển vào bộ nhớ dài hạn nếu được lặp lại hoặc có ý nghĩa, hoặc bị quên đi sau vài phút.
1.1. Bộ nhớ làm việc (Working Memory)
Là dạng bộ nhớ giúp bạn giữ và thao tác thông tin trong đầu để sử dụng ngay lập tức. Ví dụ, khi bạn:
- Giữ kết quả phép tính trung gian khi đang tính toán nhẩm.
- Nhớ tên người được nhắc ở đầu câu để hiểu ý nghĩa toàn câu.
- Giữ khái niệm “quả bóng” trong đầu và kết hợp nó với khái niệm “màu cam” để hình dung ra “quả bóng màu cam”.
Agent: Bộ nhớ ngắn hạn được thiết kế để duy trì ngữ cảnh trong phạm vi một phiên làm việc hoặc một cuộc hội thoại duy nhất. Nhờ đó, chatbot có thể xử lý các hội thoại nhiều lượt (multi-turn dialogues) một cách tự nhiên và mạch lạc. Cách hoạt động:
-
Chatbot lưu trữ tạm thời các dữ liệu như:
- Ý định hiện tại của người dùng (user intent)
- Lịch sử câu hỏi trong phiên
- Các biến trung gian cần dùng trong quá trình phản hồi
-
Toàn bộ dữ liệu này sẽ bị xóa sau khi phiên kết thúc.
- Ví dụ (trong chatbot chăm sóc khách hàng) Người dùng: “Tôi muốn kiểm tra tình trạng đơn hàng.” Chatbot: “Bạn có thể cung cấp mã đơn hàng không?” Người dùng: “Mã là 12345.”
2. Long-term Memory
Bộ nhớ dài hạn cho phép chatbot lưu trữ và ghi nhớ thông tin của người dùng qua nhiều phiên tương tác khác nhau. Đây là yếu tố cốt lõi để cá nhân hoá trải nghiệm và duy trì tính liên tục trong các tác vụ (task continuity).
2.1 Procedural Memory – Bộ nhớ quy trình (hay bộ nhớ thao tác)
Khái niệm: Bộ nhớ quy trình là trí nhớ dài hạn giúp lưu cách thực hiện một hành động hoặc kỹ năng, tương tự như “bộ lệnh lõi” của não người.
- Trong con người: là khả năng ghi nhớ cách làm một việc, ví dụ như biết đi xe đạp, đánh máy hoặc nấu ăn.
- Trong agent (tác tử AI): theo bài nghiên cứu CoALA, bộ nhớ quy trình được ví như tổ hợp giữa trọng số của mô hình ngôn ngữ (LLM weights) và mã nguồn của agent — những yếu tố định hình cách mà agent hoạt động.
Thực tế hiện nay:
- Rất ít (hoặc hầu như không có) hệ thống agent tự động cập nhật trọng số của LLM hay tự ghi đè mã nguồn của chính nó.
- Một số agent có thể tự cập nhật “system prompt” – tức phần mô tả vai trò hoặc hành vi gốc của mình – để thay đổi cách hoạt động.
- Tuy nhiên, cơ chế này vẫn khá hiếm gặp trong thực tế.
2.2 Semantic Memory – Bộ nhớ ngữ nghĩa
Khái niệm: Bộ nhớ ngữ nghĩa là kho lưu trữ lâu dài về kiến thức và sự hiểu biết về thế giới.
- Trong con người: chứa các sự kiện, khái niệm, mối quan hệ giữa các ý nghĩa — ví dụ như “Trái đất quay quanh Mặt trời” hay “Hà Nội là thủ đô Việt Nam” .
- Trong agent: bộ nhớ ngữ nghĩa là kho dữ liệu chứa các “sự thật” (facts) về thế giới.
Ứng dụng thực tế
-
Thường được dùng để cá nhân hoá trải nghiệm người dùng. Trong AI agents, semantic memory được mở rộng để trở thành “kho kiến thức có cấu trúc” mà agent có thể dựa vào để suy luận hoặc ra quyết định.
Và kho kiến thức đó không chỉ chứa sự thật “về thế giới khách quan” , mà còn có thể chứa “sự thật về người dùng” — vì đối với agent, “thông tin về người dùng” cũng là một phần của thế giới mà nó tương tác.
Ví dụ:
- “Hoàng thích cà phê hơn trà.”
- “Người dùng A sống ở Hà Nội.”
- “Người dùng này đã mua 3 sản phẩm trong 1 tháng qua.”
Những thông tin này có cấu trúc dạng fact hoặc triple (subject–predicate–object) như trong semantic knowledge graph:
User123 → prefers → coffeeUser123 → city → Hanoi→ Vì vậy, trong hệ thống agent, dữ liệu cá nhân hóa chính là một lớp con của bộ nhớ ngữ nghĩa, chỉ khác ở phạm vi (facts về người dùng cụ thể thay vì thế giới nói chung).
- Các agent hiện nay có thể trích xuất thông tin từ cuộc trò chuyện (bằng LLM) và lưu lại những chi tiết quan trọng.
- Dạng thông tin này phụ thuộc vào ứng dụng cụ thể (application-specific) .
- Sau đó, khi có tương tác mới, agent truy xuất dữ liệu đã lưu và chèn vào system prompt để ảnh hưởng đến cách phản hồi.
2.3 Episodic Memory – Bộ nhớ sự kiện
Khái niệm: Bộ nhớ sự kiện liên quan đến khả năng hồi tưởng lại các trải nghiệm cụ thể trong quá khứ.
- Trong con người: là việc nhớ lại một sự kiện hay tình huống đã từng trải qua, ví dụ “Buổi hội thảo tôi tham dự tuần trước” .
- Trong agent: đây là bộ nhớ lưu lại chuỗi hành động mà agent đã thực hiện trước đó.
Mục đích:
- Giúp agent học hỏi từ các hành động đã xảy ra, để tái hiện hành vi đúng trong tương lai.
Thực tế triển khai:
- Thường được mô phỏng thông qua few-shot prompting — tức là agent được cung cấp vài ví dụ cụ thể về các hành động “chuẩn” trong quá khứ.
- Khi có nhiều ví dụ hơn, có thể áp dụng dynamic few-shot prompting (tự chọn prompt phù hợp với ngữ cảnh).
- Bộ nhớ sự kiện rất hữu ích khi agent cần lặp lại các hành động chính xác đã từng làm trước đó, trong khi bộ nhớ ngữ nghĩa lại phù hợp khi agent liên tục phải xử lý các tình huống mới hoặc không có “đáp án đúng” cố định.
| Loại bộ nhớ | Mục đích | Khó khăn / Thách thức chính |
|---|---|---|
| Short-Term Memory | Giữ thông tin tạm thời trong phạm vi một phiên làm việc hoặc hội thoại. | - Dung lượng giới hạn → dễ mất ngữ cảnh trong hội thoại dài. - Không tồn tại sau khi phiên kết thúc - Khó xử lý khi có nhiều mục đích (intents) song song. |
| Working Memory | Lưu và xử lý thông tin tạm thời đang được “tư duy” hoặc “tính toán”. | - Tốn tài nguyên tính toán khi phải giữ nhiều biến trạng thái cùng lúc. - Khó duy trì nhất quán logic trong chuỗi suy luận phức tạp. - Dễ bị “context drift” (lệch ngữ cảnh) khi hội thoại kéo dài. |
| Long-Term Memory | Lưu trữ thông tin về người dùng, thế giới hoặc kinh nghiệm qua nhiều phiên. | - Vấn đề bảo mật và quyền riêng tư dữ liệu (GDPR, consent) - Dữ liệu cũ có thể lỗi thời, gây phản hồi sai. - Cần cơ chế quản lý, cập nhật và xoá dữ liệu hợp lý. |
| Episodic Memory | Ghi nhớ và tái hiện các sự kiện hoặc chuỗi hành động đã xảy ra trong quá khứ. | - Dữ liệu nhanh chóng phình to theo thời gian (nhiều episode). - Cần cơ chế index và tìm kiếm hiệu quả. - Khó chọn episode nào là “liên quan” nhất trong tình huống mới. |
| Semantic Memory | Lưu trữ tri thức, sự kiện, khái niệm và quan hệ giữa chúng (facts về thế giới). | - Cần thiết kế cấu trúc lưu trữ tri thức rõ ràng (ontology, schema). - Khó đồng bộ và cập nhật kiến thức mới. - Dễ dẫn đến câu trả lời lỗi thời nếu không cập nhật thường xuyên. |
| Procedural Memory | Ghi nhớ “cách thực hiện” các tác vụ – quy tắc vận hành hoặc hướng dẫn hành vi. | - Ít hệ thống agent hiện nay tự cập nhật “hành vi” của mình. - Việc cho phép agent tự thay đổi code hoặc prompt tiềm ẩn rủi ro an toàn. - Cần kiểm soát chặt chẽ để tránh “drift” hành vi ngoài ý muốn. |
| Prospective Memory | Ghi nhớ các ý định hoặc nhiệm vụ sẽ thực hiện trong tương lai. | - Khó xác định thời điểm hoặc điều kiện kích hoạt hành động. - Dễ quên hoặc kích hoạt sai khi có nhiều tác vụ song song. - Cần cơ chế scheduling, priority và reminder hiệu quả. |
| Sensory Memory | Tiếp nhận và lưu trữ thông tin đầu vào từ môi trường (âm thanh, hình ảnh, tín hiệu, v.v.) trong thời gian rất ngắn. | - Xử lý dữ liệu cảm giác (âm thanh, hình ảnh, video) tốn tài nguyên. - Cần pipeline xử lý thời gian thực (real-time). - Khó lọc nhiễu và chọn thông tin quan trọng. |
Cách cập nhật memory
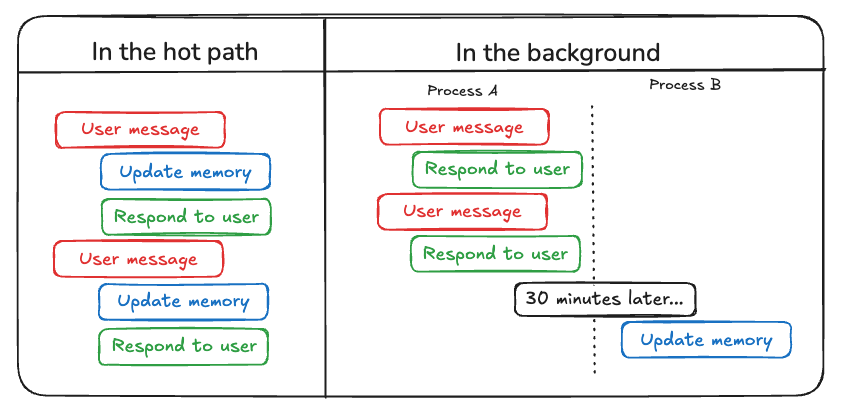
Bên cạnh việc lựa chọn loại bộ nhớ phù hợp cho agent, cần cân nhắc cách thức cập nhật bộ nhớ của agent.
Có hai hướng tiếp cận phổ biến:
1. Cập nhật “trực tiếp trong luồng xử lý” (In the hot path)
Đây là cách mà hệ thống agent chủ động ghi nhớ thông tin ngay trong quá trình phản hồi — thường được thực hiện thông qua tool calling hoặc cơ chế nội bộ của mô hình. Ví dụ: Đây là phương pháp được ChatGPT áp dụng.
Ưu điểm:
- Bộ nhớ được cập nhật ngay lập tức.
- Thông tin mới có thể ảnh hưởng trực tiếp đến phản hồi kế tiếp.
Nhược điểm:
- Làm tăng độ trễ (latency) trước khi phản hồi được gửi đi.
- Logic xử lý bộ nhớ và logic phản hồi bị trộn lẫn, khó tách biệt để bảo trì.
2. Cập nhật trong nền (In the background)
Ở hướng này, một quá trình nền (background process) sẽ chạy song song hoặc sau khi hội thoại kết thúc để cập nhật bộ nhớ.
Ưu điểm:
- Không làm tăng độ trễ trong khi hội thoại.
- Logic về bộ nhớ tách biệt khỏi luồng xử lý chính, dễ bảo trì hơn.
Nhược điểm:
- Bộ nhớ không được cập nhật ngay lập tức.
- Cần thêm logic để xác định khi nào nên kích hoạt quá trình cập nhật nền.
3. Cập nhật dựa trên phản hồi người dùng (User feedback-based updating)
Cách này đặc biệt hữu ích cho Episodic Memory (trí nhớ sự kiện) . Ví dụ: Nếu người dùng đánh dấu một tương tác là tốt, hệ thống có thể lưu phản hồi tích cực đó để tham chiếu và ưu tiên trong các tương tác tương lai.
Các Memory layer trên thị trường
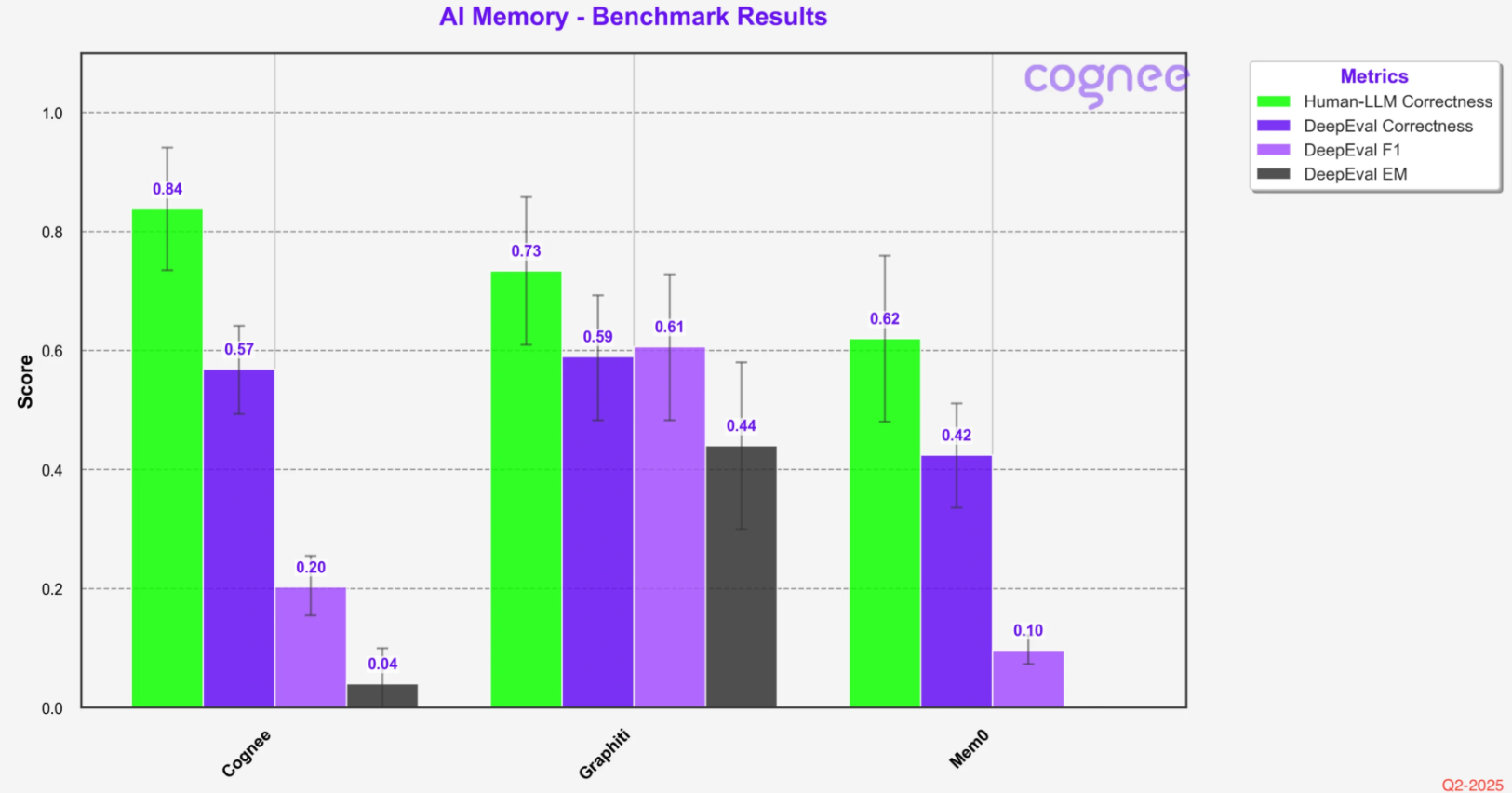
Cognee
Cách Cognee hoạt động (biến dữ liệu thô thành hệ thống tri thức.)
1. add() – Nạp dữ liệu đầu vào
Hàm add() là điểm khởi đầu của quá trình ingest dữ liệu, cho phép tiếp nhận nhiều định dạng khác nhau như JSON, Markdown hoặc phản hồi từ API.
Dữ liệu sau đó được chuẩn hoá và tiền xử lý, chuẩn bị cho bước xây dựng đồ thị tri thức (knowledge graph).
2. cognify() – Trí tuệ hóa dữ liệu
Đây là bộ máy chuyển đổi cốt lõi của Cognee.
cognify() sử dụng LLM để:
- Trích xuất thực thể (entities)
- Nhận diện mối quan hệ (relationships)
- Cấu trúc dữ liệu thành đồ thị tri thức có thể truy xuất (traversable knowledge graph)
3. search() – Tìm kiếm và truy vấn tri thức
Thông qua search(), người dùng có thể tương tác trực tiếp với đồ thị tri thức bằng:
- Truy vấn ngôn ngữ tự nhiên (natural language queries), hoặc
- Truy vấn có cấu trúc (Cypher expressions).
Hệ thống hiểu ngữ cảnh và quan hệ giữa các nút trong graph, từ đó trả về kết quả có liên quan và có ý nghĩa.
4. memify() – Tạo lớp trí nhớ thông minh
Hàm memify() áp dụng thuật toán suy luận nâng cao, nhằm phát hiện các kết nối ngầm định và rút ra quy tắc từ dữ liệu.
Kết quả là một lớp bộ nhớ động (dynamic memory layer) giúp:
- Cải thiện khả năng tìm kiếm, và
- Khám phá những mối quan hệ tiềm ẩn mà dữ liệu gốc không thể hiện rõ.
Cognee Architecture
1. Sử dụng multiple stores
Cognee kết hợp ba hệ thống lưu trữ bổ trợ lẫn nhau, mỗi hệ đảm nhận một vai trò riêng — và khi phối hợp cùng nhau, chúng giúp dữ liệu của bạn vừa có thể tìm kiếm được, vừa có tính kết nối.
- Relational store (Kho quan hệ) — Theo dõi tài liệu, các đoạn (chunks) và nguồn gốc dữ liệu (provenance) — tức là dữ liệu đến từ đâu và liên kết thế nào với nguồn ban đầu.
- Vector store (Kho vector) — Lưu trữ embedding để phục vụ cho tìm kiếm theo ngữ nghĩa tương đồng — tức là các biểu diễn số giúp Cognee tìm ra các đoạn văn bản có ý nghĩa gần nhau, ngay cả khi cách diễn đạt khác nhau.
- Graph store (Kho đồ thị) — Lưu trữ thực thể (entities) và mối quan hệ (relationships) dưới dạng đồ thị tri thức (knowledge graph) — giúp Cognee hiểu cấu trúc và điều hướng giữa các khái niệm.
2. Cách các kho được sử dụng (How they are used)
Mỗi loại lưu trữ đóng vai trò khác nhau tùy theo giai đoạn xử lý:
- Relational store: Đóng vai trò trọng tâm trong giai đoạn cognification — nơi hệ thống theo dõi tài liệu, các đoạn và nguồn gốc của từng phần thông tin.
-
Vector store và Graph store: Phát huy vai trò trong giai đoạn tìm kiếm và truy xuất (search & retrieval) :
- Tìm kiếm ngữ nghĩa (Semantic Search) – sử dụng vector embeddings để tìm các đoạn văn bản có nội dung liên quan về mặt ý nghĩa.
- Tìm kiếm cấu trúc (Structural Search) – sử dụng đồ thị tri thức và truy vấn Cypher để khám phá các mối quan hệ giữa thực thể.
- Tìm kiếm lai (Hybrid Search) – kết hợp hai cách trên để mang lại kết quả vừa chính xác về ngữ cảnh, vừa rõ ràng về cấu trúc.
Mem0
Cách Mem0 hoạt động (biến dữ liệu thô thành hệ thống tri thức.)
- Add (Thêm mới): Nếu thông tin mới là duy nhất và có liên quan, nó sẽ được thêm vào kho bộ nhớ.
- Update (Cập nhật): Nếu thông tin mới tương tự một memory hiện có nhưng bổ sung thêm chi tiết, hệ thống sẽ cập nhật memory cũ.
- Delete (Xóa bỏ): Nếu thông tin mới trùng lặp hoặc không liên quan, nó sẽ bị loại bỏ.
- Merge (Hợp nhất): Nếu thông tin mới có thể kết hợp với memory hiện có để tạo thành một mục toàn diện hơn, hai memory sẽ được hợp nhất lại.
- Information Extraction (Trích xuất thông tin): Dữ liệu đầu vào được phân tích qua LLM để rút trích các thông tin quan trọng như: sự kiện, quyết định, sở thích hoặc dữ kiện đáng ghi nhớ.
- Conflict Resolution (Xử lý mâu thuẫn): Mem0 so sánh memory mới với dữ liệu đã có nhằm phát hiện trùng lặp hoặc mâu thuẫn, sau đó cập nhật hoặc ghi đè khi cần thiết.
- Memory Storage (Lưu trữ bộ nhớ): Kết quả được lưu vào cơ sở dữ liệu vector (phục vụ tìm kiếm ngữ nghĩa) và tùy chọn lưu thêm vào cấu trúc đồ thị (graph) để ánh xạ quan hệ giữa các thông tin.
- Query Processing (Xử lý truy vấn): LLM hỗ trợ phân tích truy vấn người dùng, kết hợp với Vector Search (dựa trên cosine similarity) để tìm các memory liên quan về ngữ nghĩa.
- Filtering & Ranking (Lọc và xếp hạng): Các memory được lọc logic và xếp hạng theo độ liên quan.
- Results Delivery (Trả kết quả): Hệ thống trả về các memory phù hợp, kèm metadata như timestamp và nguồn gốc để duy trì tính nhất quán ngữ cảnh.
Tại sao memory không lưu trữ thông tin
Cơ chế Lọc của Mem0: Mem0 chỉ lưu trữ thông tin có giá trị lâu dài hoặc liên quan đến cá nhân/ngữ cảnh. → Loại bỏ dữ liệu chung chung, tạm thời để tránh làm “rác” bộ nhớ.
Những loại thông tin không được ghi nhớ
- Định nghĩa khái niệm: “Machine learning là gì?”
- Kiến thức phổ thông: “Bầu trời có màu xanh.”
- Lý thuyết trừu tượng, không gắn với trải nghiệm cá nhân
- Chào hỏi, filler trong hội thoại
- “Tôi học Machine Learning hôm qua” → ✅ Có tính cá nhân, được lưu.
- “Machine Learning là lĩnh vực của AI” → ❌ Chung chung, bị bỏ qua.
Cách giúp thông tin dễ được lưu hơn
- Thêm yếu tố thời gian: “Hôm qua”, “trong buổi họp”
- Gắn với bản thân hoặc ngữ cảnh: “Tôi nghĩ…”, “Tôi thích…”
- Cụ thể, có ví dụ thực tế
- Tránh nói chung chung
Làm thế nào mem0 biết thông tin nào quan trọng
LLM + NLP
Mem0 sử dụng LLM (GPT, Claude, Groq, Ollama, v.v.) để:
- Phân tích ngữ nghĩa, ngữ cảnh và ý định trong đoạn hội thoại
- Nhận diện sự kiện, thực thể, sở thích, mục tiêu của người dùng
- Quyết định thông tin nào xứng đáng được lưu vào bộ nhớ dài hạn
Mem0 kết hợp nhiều kỹ thuật xử lý ngôn ngữ tự nhiên để tinh lọc dữ liệu:
- Named Entity Recognition (NER): Xác định tên người, địa điểm, dự án
- Relation Extraction: Phát hiện mối quan hệ giữa các thực thể
- Sentiment Analysis: Hiểu thái độ/cảm xúc (e.g., “dislikes cheese”)
- Coreference Resolution: Liên kết đại từ với đối tượng đúng (e.g., “he” → “Alex”)
- Summarization: Tóm gọn thông tin dài thành đơn vị ký ức ngắn
- Fact Extraction: Tách ra các câu khẳng định hoặc dữ kiện quan trọng
Cấu trúc dữ liệu của 1 đơn vị ký ức
- id: Mã định danh duy nhất (UUID)
- memory: Nội dung chính được lưu trữ
- hash: Dấu vân tay nội dung, dùng để phát hiện thay đổi
- created_at / updated_at: Thời điểm tạo & cập nhật (ISO 8601)
- expiration_date: (Tuỳ chọn) Ngày hết hạn
-
immutable: Cờ cho biết memory có được phép sửa đổi hay không
-
Mem0 gắn thêm metadata phong phú giúp truy vấn và phân loại dễ hơn:
- Timestamps: Theo dõi vòng đời bộ nhớ
-
Identifiers
- user_id → Phân vùng theo người dùng
- agent_id → Gắn với agent cụ thể
- run_id → Gom nhóm các memory cùng phiên hoặc task
- Custom Metadata: Lưu thông tin tùy chỉnh ((ví dụ: { “topic”: “travel”, “priority”: “high” })
- Categories: Nhãn tự động hoặc do dev gán (e.g., “personal_details”, “food”): Nhãn tự động hoặc do dev gán (e.g., “personal_details”, “food”)
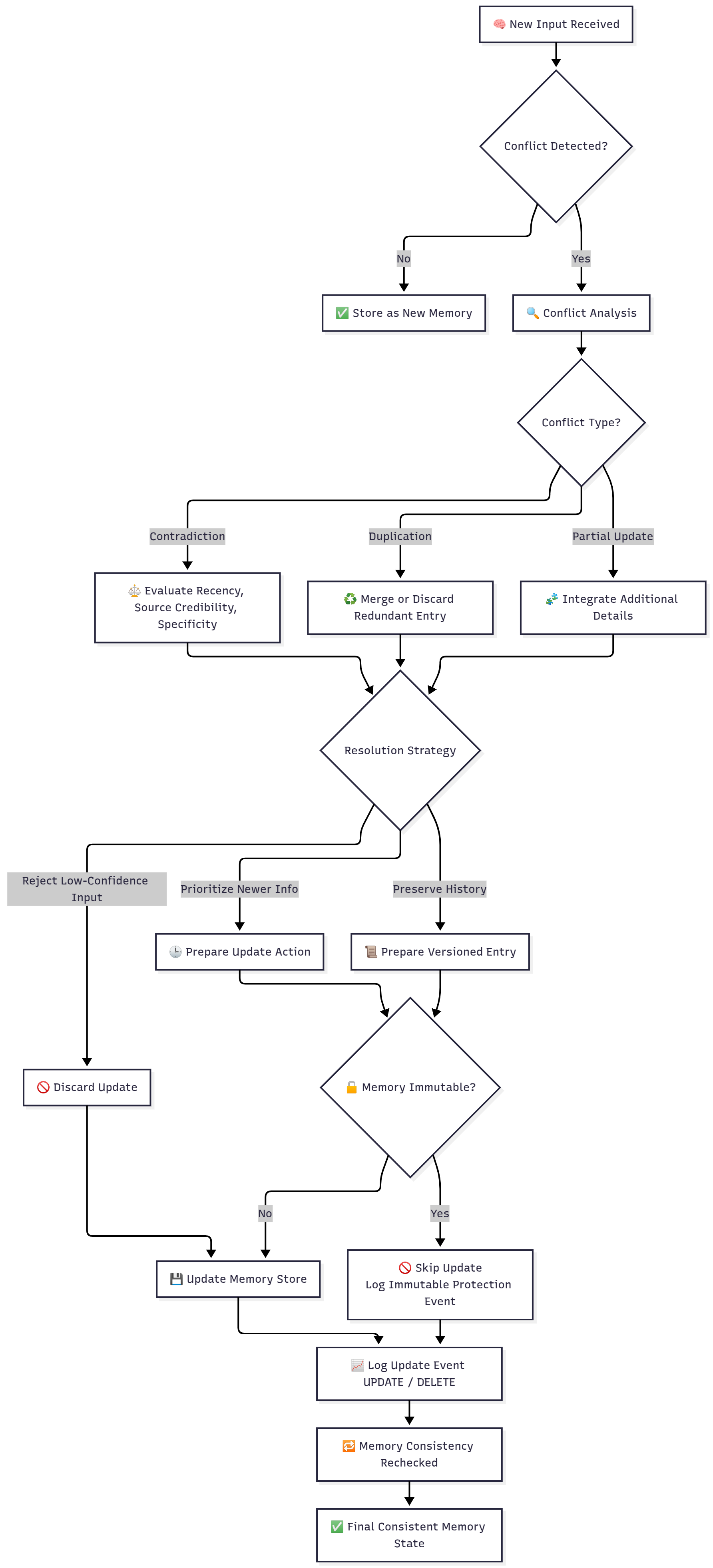
Xử lý mâu thuẫn Conflicts, inconsistencies trong Memory
Nếu hôm nay tôi thích uống trà, ngày mai thì không?
Mem0 không lưu trữ ký ức tĩnh — nó xử lý liên tục, thích ứng với thông tin mới.
- Khi dữ liệu mới trái ngược với ký ức cũ (ví dụ: người dùng nói “Giờ tôi thích uống trà” sau khi từng nói “Tôi không thích uống trà”), Mem0 sẽ kích hoạt logic giải quyết xung đột.
- Cơ chế xử lý:.
- Phát hiện mâu thuẫn — Xác định các ký ức nói về cùng một chủ đề.
- Đánh giá và chọn lọc — Chọn thông tin mới hơn (dựa theo timestamp), vì được xem là trạng thái hiện tại.
- Cập nhật bộ nhớ — Có thể:
- Ghi đè ký ức cũ,
- Đánh dấu là “đã lỗi thời”, hoặc
- Tạo phiên bản mới, vẫn giữ lịch sử cũ