Agent Cost ≠ App Cost: tại sao cách tính Ops/Cost của các ứng dụng thông thường không áp dụng được với Agent
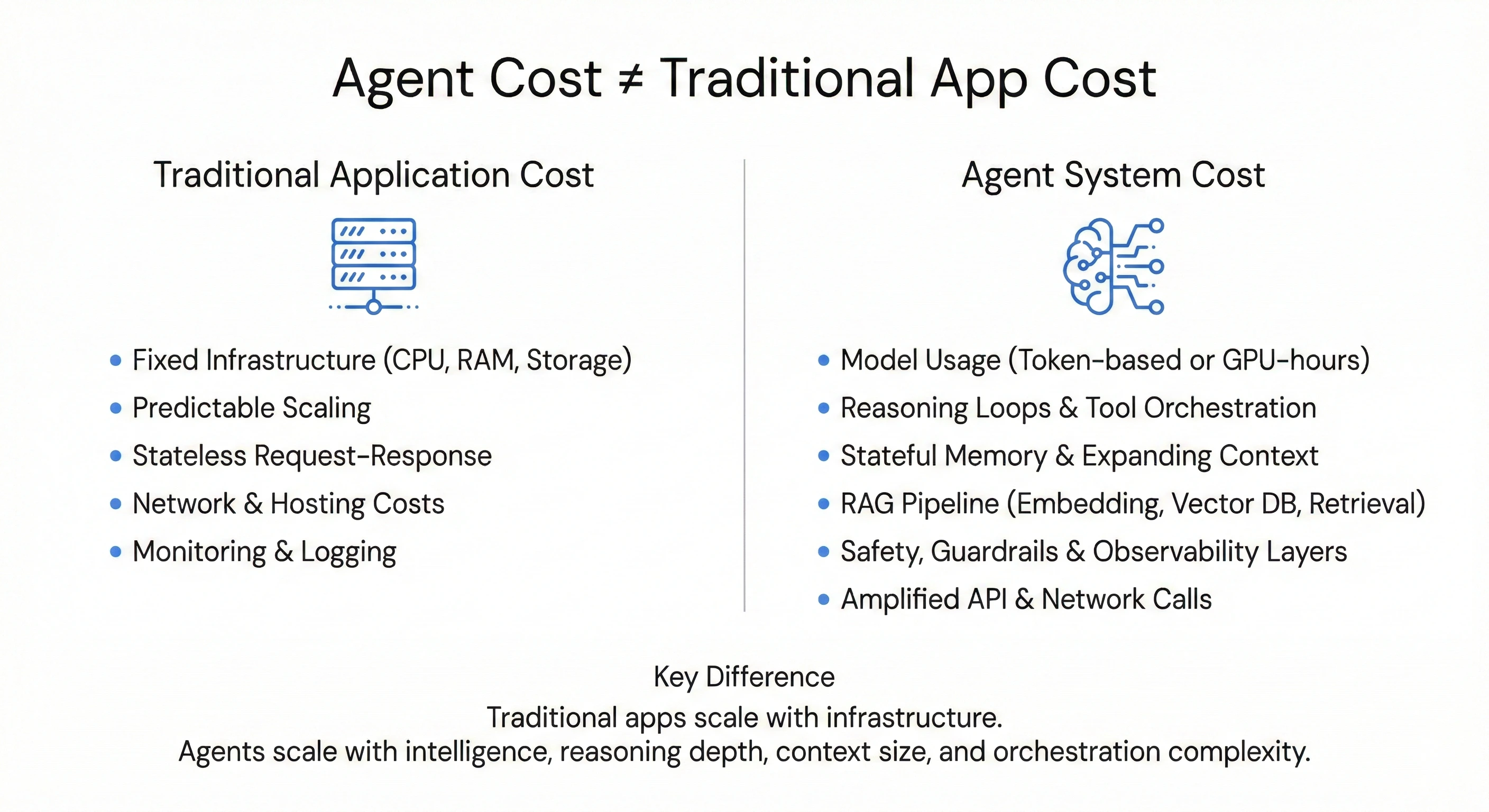
1. Những chi phí phát sinh mà application thông thường không có
-
Model usage: Đây thường là khoản chi phí lớn nhất. Thay vì chỉ trả tiền Infra cố định như CPU/RAM/Disk,.., ta phải trả theo token (khi dùng qua API như OpenAI, Gemini, Claude,..) hoặc theo GPU-hours nếu tự host model open-source. Mỗi input prompt, output, cả lượng token để reasoning của LLM đều bị tính phí.
-
Reasoning loops & Tool orchestration: Trong kiến trúc agentic, một query không phải là một request/response đơn lẻ. Nó là một workflow e2e: plan → reason → act → observe → refine. Mỗi bước trong vòng lặp đó - từ các lần gọi LLM để suy luận cho đến việc gọi các tool/api bên ngoài cũng đều được tính.
-
Stateful memory & Context:
Khác với các hệ thống stateless truyền thống, Agent cần duy trì trạng thái hội thoại. Mỗi lượt xử lý vì thế phải tái xây dựng context từ lịch sử đã có, khiến kích thước ngữ cảnh tăng dần theo thời gian. Session càng dài, context càng nhiều.
Song song đó, RAG và Vector DB gần như trở thành một thành phần bắt buộc. Pipeline embedding → indexing → similarity search → context assembly bổ sung thêm một lớp chi phí về storage và compute, tách biệt với chi phí model.
- Safety, Guardrails & Observability: Xây dựng agent trên môi trường production đòi hỏi thêm nhiều lớp bảo vệ: PII, policy, và tracing, observability để debug các luồng reasoning nhiều bước. Mỗi lớp bảo vệ bổ sung thường đi kèm với các lần gọi model hoặc service riêng biệt. Vì vậy, chi phí không chỉ nằm ở luồng chính, mà còn ở các cơ chế bảo vệ chạy song song phía sau. Token scale theo
- Amplified networking: Agent thường xuyên tương tác với nhiều API bên thứ 3 (hoặc nội bộ). Điều này có thể làm tăng chi phí network egress và phí sử dụng API bên thứ ba. Trong một số trường hợp, tổng chi phí networking và API thậm chí có thể vượt cả mức egress của các ứng dụng truyền thống.
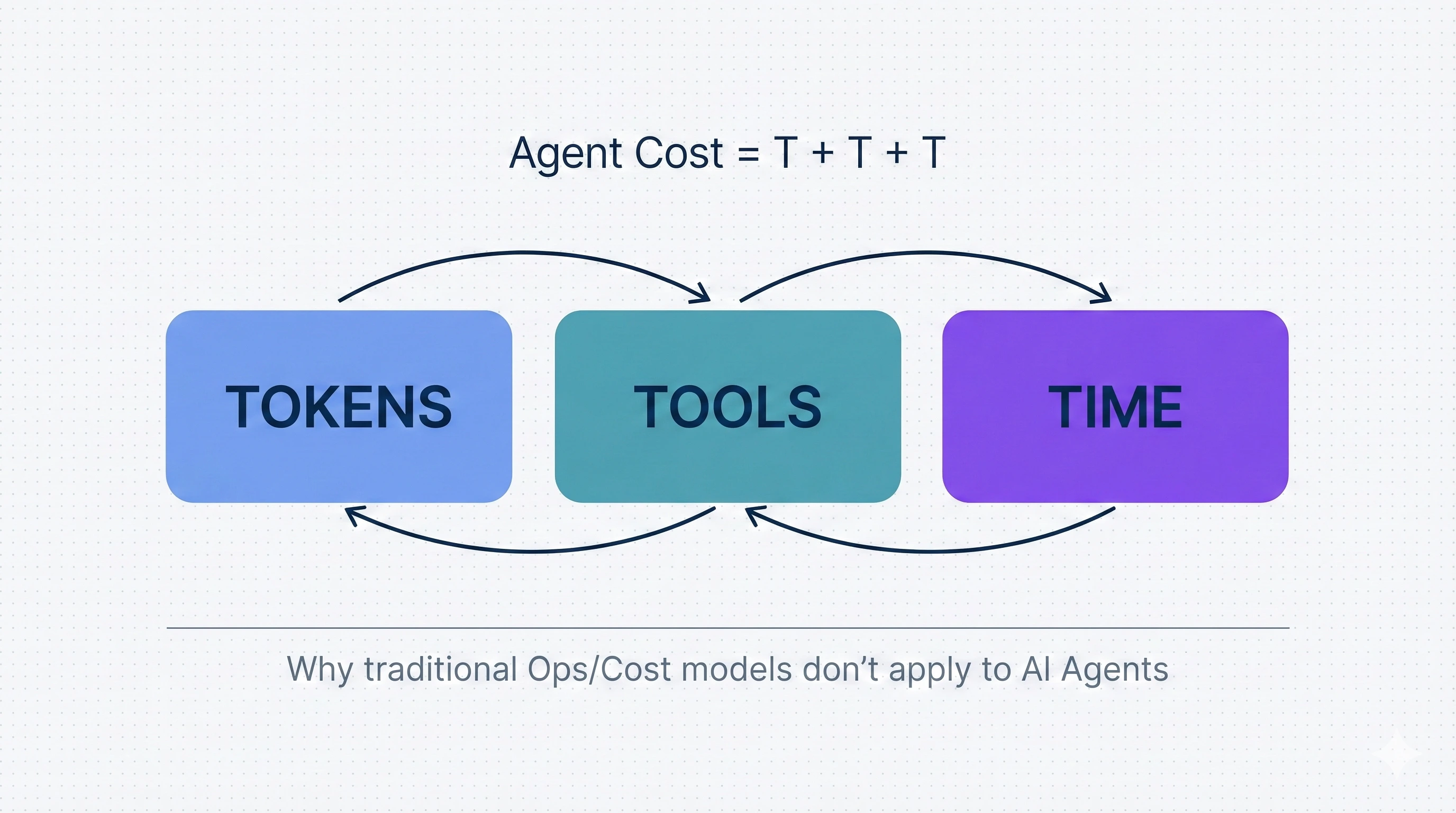
2. Agent Cost = Tokens + Tools + Time (TTT)
TTT giống như một “định luật bảo toàn chi phí” của Agent. Giống CAP Theorem trong hệ thống phân tán, ta luôn phải đánh đổi 2 trên 3 tham số.
2.1 Tokens
Đây thường là chi phí lớn nhất. Agent không chỉ “trả lời”. Nó suy nghĩ.
Token được tính cho ba việc:
-
Reasoning: Các bước suy luận nội bộ (chain-of-thought, planning loop). User không thấy, nhưng vẫn phải trả tiền.
-
Context Inflation: Session càng dài, prompt càng to. Request thứ 10 đắt hơn request thứ 1.
-
Guardrails & Eval: Model phụ chạy song song để kiểm duyệt, kiểm tra policy, scoring.
2.2 Tools
Trong mô hình Agent, hệ thống không tự xử lý mọi thứ mà sẽ tương tác với các dịch vụ bên ngoài thông qua nhiều tool khác nhau. Ví dụ, chỉ với một yêu cầu đơn giản như “Check đơn hàng”, Agent có thể phải thực hiện API fan-out, tức là gọi đồng thời nhiều hệ thống như CRM, Shipping, Inventory, Refund Policy và Billing; việc một request kích hoạt 3–5 tool calls là hoàn toàn bình thường.
Quá trình orchestration (điều phối) này dẫn đến egress và các external API calls, đồng nghĩa với việc phát sinh chi phí về API usage và network khi Agent giao tiếp với các hệ thống bên ngoài.
2.3 Time
Nếu Token là chi phí của “suy nghĩ”, thì Time là chi phí của “tồn tại”. Ta trả tiền cho hạ tầng:
- vCPU
- RAM
- Instance hours
- Idle time (đợi LLM/tool trả lời nhưng instance vẫn sống)
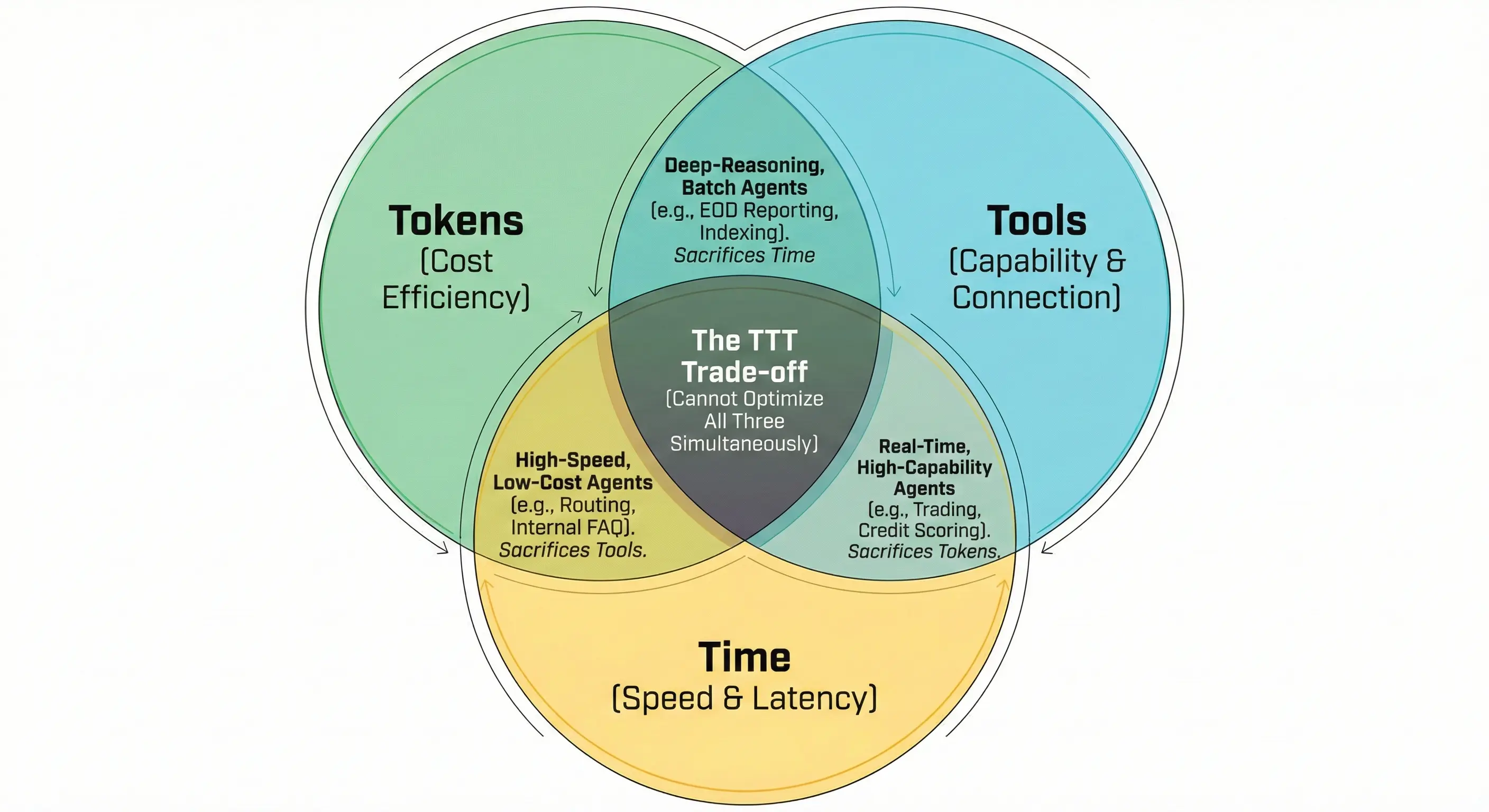
Giống CAP Theorem, ta không thể tối ưu đồng thời Time, Token và Tool - mỗi quyết định tối ưu một tham số sẽ ảnh hưởng sang hai tham số còn lại, tùy vào bài toán biz hãy chọn tham số nào là lợi thế cạnh tranh (nhanh hơn, rẻ hơn, hay mạnh hơn) từ đó chủ động thiết kế hệ thống để kiểm soát ở hai tham số còn lại, vì chi phí không biến mất, nó chỉ chuyển từ dạng này sang dạng khác.
3. Cách định giá
Sau khi hiểu TTT vận hành như nào, câu hỏi quan trọng tiếp theo không phải là tốn bao nhiêu, mà là định giá như thế nào để phản ánh đúng bản chất của agent và dưới đây là 3 cách tiếp cận phổ biến nhất.
3.1 – Per-request (Unit Economics)
Câu hỏi:
Một request tốn bao nhiêu tiền?
Đây là chi phí đơn vị, đo lường chi phí cho một request đơn lẻ tiêu tốn bao nhiêu tiền
Token Cost
Khác với một yêu cầu LLM thông thường (Input -> Output), Agent hoạt động theo vòng lặp (Loop). Công thức tính là:
\[C_{token} = \sum_{step=1}^{k} \left( T_{in, step} \times P_{in} + T_{out, step} \times P_{out} \right)\]Trong đó:
- k: Số bước suy luận (iterations) để hoàn thành task.
- T_in: Tổng token đầu vào ở mỗi bước (bao gồm System Prompt, Tool Definition, Lịch sử hội thoại, và kết quả từ Tool của bước trước).
- T_out: Token đầu ra ở mỗi bước (bao gồm Reasoning/Chain of Thought và lệnh gọi Tool).
- P_in: chi phí xử lý token input (ví dụ: $2 / 1M input token)
- P_out: chi phí xử lý token output (ví dụ: $10 / 1M output token)
Tool Cost:
\[C_{tools} = \sum_{i=1}^{n} (P_{ext,i} + P_{token,i} + P_{infra,i})\]Trong đó:
- n: Số lượng tool call trung bình để hoàn thành một task. (Ví dụ: 1 user request → 3 tool calls)
- External_Fee: Phí trực tiếp từ nhà cung cấp API. (Ví dụ: $0.001/call)
- Token_Cost: Chi phí token để LLM xử lý (ví dụ: $2 / 1M input token)
- Infra_Cost: Chi phí băng thông egress hoặc compute để xử lý trung gian dữ liệu giữa Agent và Tool.
Time Cost:
\[C_{time} = (vCPU \cdot L + GiB \cdot L) \cdot \$_{infra}\]Trong đó: L - là thời gian xử lý thực tế (ví dụ: 0.004 hour, vì đơn giá hạ tầng hay cloud thường tính theo giờ: 4$/hour)
Mục đích: Tính xem 1 request tốn bao nhiêu lúc runtime? Dùng để chứng minh các phương pháp tối ưu (prompting, caching, async tool, model tunning).
- Giảm 20% token → giảm trực tiếp cost/session
- Giảm tool call từ 5 tool xuống 2 tool → giảm cost
- Caching → giảm cả Token lẫn Time
3.2 – Concurrency / Sessions
Câu hỏi:
Peak có bao nhiêu user active cùng lúc?
Ở đây Tokens và Tools không chỉ là tiền — chúng là quota và rate limit.
Concurrency đo lường tại thời điểm cao nhất trong ngày, có bao nhiêu user đang tương tác với hệ thống cùng lúc?
Tham số này bỏ qua từng request riêng lẻ mà tập trung vào số lượng người dùng đồng thời tối đa mà hệ thống phải đáp ứng, đảm bảo độ tin cậy Agent không sập vào giờ cao điểm.
Mục đích: Đo lường cần bao nhiêu capacity lúc peak để bảo vệ latency p95? Dùng để đặt giá trị max_instances.
Tokens Cost:
\[TPM_{required} = \frac{Peak\_C \cdot T_{total\_per\_session}}{Duration_{session}}\](TPM: Tokens Per Minute - đơn vị đo “băng thông” của model provider, tức lượng token tối đa có thể đi qua hệ thống trong một phút)
Tools Cost:
\[RPM_{tool} = Peak\_C \cdot n \cdot P_{buffer}\](RPM: Requests Per Minute - Giới hạn của hệ thống backend/API).
Time Cost:
\[C_{peak} = Peak\_C \cdot (vCPU_{sess} + RAM_{sess}) \cdot H_{peak}\](Trong đó: Peak_C là Peak Concurrent Sessions).
Vấn đề phát sinh
1. Token Rate Limit (TPM/RPM)
Nếu 100 session đồng thời và mỗi session đốt 2,000 token:
- API có đủ TPM không?
- Nếu vượt giới hạn → 429 → Agent không trả lời.
2. Tool Backend Capacity
100 user cùng gọi CRM:
- Backend hiện tại có chịu tải được không?
- Retry → giữ session lâu hơn → tăng Time cost.
Ở cách tính này này:
- Tokens = quota pressure
- Tools = backend stress
- Time = compute capacity
3.3 – Shape / Window
Trong cách tính Shape / Window, ta không tính “mỗi request tốn bao nhiêu tiền”, mà dựa vào mức độ sử dụng tài nguyên của toàn hệ thống và khung thời gian vận hành thực tế (giờ cao điểm, ngày, tháng) để map đúng với hóa đơn từ Cloud Provider hay SaaS, chuyển tư duy từ cost per request sang cost theo footprint và theo chu kỳ, vì nhà cung cấp tính tiền theo tải, theo thời gian và theo tổng volume chứ không theo từng request riêng lẻ.
Token Cost
\[C_{total\_token} = \sum (Tokens_{Realtime} \times P_{standard}) + \sum (Tokens_{Batch} \times P_{discount})\]Kèm theo điều kiện:
\[Max(Tokens_{Realtime} / Minute) \leq Shape_{TPM}\]Giống như giá điện, chi phí Token cũng có khái niệm Window (Khung thời gian) nhờ các chế độ như Batch API.
- Peak Window (Giờ cao điểm): Các request cần phản hồi ngay lập tức (Real-time Agent) phải chấp nhận giá niêm yết 100%.
- Off-Peak Window (Giờ thấp điểm): Với các tác vụ Agent không cần gấp (như quét báo cáo cuối ngày, tổng hợp dữ liệu, indexing RAG), có thể đẩy vào Batch Window (thường là 24h).
Tool Cost
\[C_{tool} = \sum (Calls_{total} \cdot P_{tool})\]Time Cost
\[C_{time} = (Inst_{peak} \cdot H_{peak} + Inst_{off} \cdot H_{off}) \cdot P_{instance\_hour}\]Trong đó:
- Inst: Số lượng máy chủ/container được triển khai.
- H: Số giờ hoạt động (chia theo Peak/Off-peak).
- P: Đơn giá cho mỗi đơn vị (Token, vCPU, Tool call).
4. Tổng kết
Việc quản trị chi phí cho AI Agent không nằm ở việc căn ke từng token, mà là dựa vào bản chất của bài toán để áp dụng đúng phương pháp đo lường. Việc lựa chọn cách tính sẽ phụ thuộc vào mục tiêu và giai đoạn của hệ thống:
- Unit Economics (Per-request): Sử dụng trong giai đoạn R&D và Tối ưu hóa (Optimization) . Cách tính này giúp các Dev, SA đo lường hiệu quả của việc tối ưu prompt, thiết kế lại các luồng suy luận (reasoning loops), hoặc đánh giá xem việc thay thế model này bằng model khác sẽ tác động thế nào đến chi phí và kết quả.
- Concurrency / Sessions: Sử dụng khi Sizing & Capacity Planning. Đây là lớp bảo vệ trước khi triển khai production: xác định max instances, đặt rate limits (TPM/RPM), đảm bảo hệ thống không sập khi traffic tăng đột biến.
- Shape / Window: Là công cụ dành cho Quản trị tài chính, FinOps. Cách tiếp cận này giúp khớp nối bức tranh kỹ thuật với hóa đơn thực tế từ Cloud Provider. Nó tối ưu hóa dòng tiền dựa trên chu kỳ vận hành thay vì từng request đơn tẻ.
Best practice khi thiết kế Costing & Sizing:
- Lấy SLA làm trọng tâm: Với đánh đổi TTT, ta không thể tối ưu cả 3. Đối với các hệ thống lõi đòi hỏi tính chính xác, bảo mật và độ tin cậy tuyệt đối (ví dụ: tư vấn danh mục đầu tư, thẩm định hồ sơ, hoặc xử lý giao dịch), ưu tiên đầu tư vào Tools (các lớp Guardrails kiểm duyệt, RAG với độ chính xác cao) và Time (hạ tầng dự phòng cho Peak time). Chấp nhận mức chi phí Tokens cao hơn ở luồng suy luận để đổi lấy sự an toàn và chính xác.
- Phân luồng nghiệp vụ theo “Khung giờ” (Routing by Urgency): Tận dụng tối đa Shape/Window. Tách bạch rõ các tác vụ cần phản hồi ngay (Real-time như tư vấn trực tiếp) với các tác vụ có thể chờ (như quét báo cáo cuối ngày, tổng hợp dữ liệu, indexing RAG). Đẩy tối đa các tác vụ chạy ngầm vào khung giờ thấp điểm (Off-peak) hoặc sử dụng Batch API
- Thiết lập (Circuit Breakers) từ ban đầu: Khi sizing hệ thống, rủi ro lớn nhất không phải là lượng user, mà là việc một Agent bị kẹt trong infinite loop hoặc retry liên tục API đang lỗi. Luôn phải thiết kế các cơ chế timeout, giới hạn số bước suy luận tối đa (max iterations) và số lần gọi tool tối đa cho mỗi session để bảo vệ hạn mức TPM/RPM của toàn hệ thống khỏi bị cạn kiệt.